domingo, 9 de diciembre de 2012
JESS
La base del conocimiento en JESS
Antes de explicar cómo expresar el conocimiento en JESS, se debe entender qué es un Sistema Experto, ya que JESS se puede comportar como tal.
Un Sistema Experto es un Sistema Basado en Conocimiento con información precisa de un dominio y con capacidad de aprendizaje sobre él y que llega a trabajar de forma similar a una persona especializada en ese dominio. Está formado por:
- Base de conocimientos (BC): contiene conocimiento modelado extraído del diálogo con el experto.
- Base de hechos (BH) (Memoria de trabajo): contiene los hechos sobre un problema que se ha descubierto durante el análisis y pueden ir aumentando a medida que se descubran nuevos hechos en los ciclos de inferencia.
- Motor de inferencia: modela el proceso de razonamiento humano. Es el que decide qué reglas de inferencia ejecutar siguiendo los pasos de un algoritmo.
- Módulos de justificación: Explica el razonamiento utilizado por el sistema para llegar a una determinada conclusión.
- Interfaz de usuario: es la interacción entre el Sistema Experto y el usuario, y se realiza mediante el lenguaje natural.

EL MOTOR DE INFERENCIA
El Motor de Inferencia se basa en la información que hay en la Base del Conocimiento y en un algoritmo para responder preguntas. Hay dos estrategias que se han explicado anteriormente: el encadenamiento hacia delante (que usa JESS) y el encadenamiento hacia atrás.
Cada vez que haya una pregunta por resolver, se buscará la solución siguiendo el algoritmo elegido y muchas veces se podrá obtener nueva información en forma de hechos. A esto se le llama el Ciclo de Inferencia:
- Se buscan todas las posibles reglas aplicables, es decir, que son compatibles con la BH.
- Se selecciona una de las reglas según un orden de preferencia.
- Se aplica la regla seleccionada y se actualiza la BH.
El problema es que en el paso 1 se comparan todas las reglas con los elementos de la Memoria de Trabajo. La solución (que usa JESS) es usar el algoritmo RETE (Algoritmo de Redundancia Temporal) que genera el conjunto de reglas aplicables del paso 1 de forma incremental.
INSTALACIÓN
Hay que tener en cuenta que JESS es un software privado por lo que, a no ser que lo compres o consigas una licencia académica, tendrás que contentarte con una versión que caduca a los 30 días.
La distribución la puedes conseguir en la zona de descargas de la página principal de JESS: http://www.jessrules.com/jess/download.shtml. Cuando hayas completado los campos y hayas aceptado puedes ver las versiones disponibles de JESS. Mi consejo es que elijas la última versión estable y la guardes. Una vez conseguida la versión descomprímela en c:\.
Luego, en Panel de Control – Sistema – Opciones Avanzadas - Variables de Entorno dentro de Variables del Sistema hay una variable llamada CLASSPATH (sino créala), haz doble clic en ella y añade al final la ruta de los .jar:
| ;c:\Jess70p2\lib\jess.jar;c:\ Jess70p2\lib\jsr94.jar |
Ahora ya puedes ejecutar JESS y empezar a trabajar con él.
EJECUTAR JESS
En una ventana Windows vete a c:\Jess70p2 (podrías hacerlo también desde c:\, pero no te aseguro que funcione siempre) y teclea:
EJECUTAR JESS
En una ventana Windows vete a c:\Jess70p2 (podrías hacerlo también desde c:\, pero no te aseguro que funcione siempre) y teclea:
| java jess.Main |
Entonces te debe aparecer lo siguiente o algo similar, teniendo en cuenta que puedes tener una versión de prueba:
| Jess, the Rule Engine for the Java Platform Copyright (C) 2006 Sandia Corporation Jess Version 7.0p1 12/21/2006 Jess> |
Si no quieres usar la ventana de Windows puedes ejecutar el modo consola de JESS:
| java jess.Console |
Aparecerá una ventana nueva con una interfaz más amistosa y que funcionará igual que la ventana de Windows:

SALIR DE JESS
Para salir de JESS, simplemente hay que teclear:
| (exit) |
CARGAR UN PROGRAMA
Todas las llamadas que hagamos a JESS van a ser entre paréntesis ().Para cargar un archivo JESS (con extensión .clp) hecho anteriormente:
| (batch nombrePrograma.clp) |
Y aparecerá TRUE escrito en la consola si está bien cargado. Por ejemplo, si cargamos el programa holaMundo.clp (enlace al archivo al final de la página):
| Jess> (batch holaMundo.clp) Hola, mundo!!! |
El intérprete supone que el programa está en c:\Jess70p2, pero si está en otra carpeta más adentro se debe especificar, por ejemplo:
| (batch ejemplo1/nombrePrograma.clp) |
Otro modo sería ejecutar JESS y cargar el programa todo a la vez:
| java jess.Main nombrePrograma.clp |
De este modo, una vez terminado de ejecutarse el programa, saldría de JESS.
Nota:
Si quieres abrir un archivo .clp para ver su contenido, ábrelo con un editor de textos como el bloc de notas. Haciendo doble clic abre el portapapeles con lo último que hayas escrito, pero no muestra el código.
ALGORITMOS GENÉTICOS
CONTENIDO
— ¿Qué son los algoritmos genéticos?
— ¿Cómo funcionan?
— Implementación de los AG
— Aplicaciones
— Representación
— Conclusiones
Inteligencia Artificial
— Problemas que no se pueden resolver por un enfoque algorítmico tradicional.
— Nueva forma de manejar la imprecisión y la incertidumbre.
— Algoritmos basados en los principios de la evolución natural .
— Se utilizan en problemas donde no se pueden encontrar soluciones o estas no son satisfactorias
Algoritmo Genético?
— Se aplican sobre una población representada de forma abstracta como cromosomas, que son la codificación de soluciones candidatas a un problema.
— La evolución comienza desde una población aleatoria.
— En cada generación, la selección natural elegirá que individuos son aptos, modificandolos y mutándolos para la siguiente generación.
— “Los Algoritmos Genéticos son algoritmos matemáticos de optimización de propósito general basados en mecanismos naturales de selección y genética, proporcionando excelentes soluciones en problemas complejos con gran número de parámetros”.
— ¿Cómo funcionan?
— Para resolver un problema usando AG necesitamos:
— Representar soluciones.
— Tradicionalmente una cadena de bits.
— Medir la calidad de cada solución con respecto al problema a resolver.
— Se usa una función de selección.
— Esquema de funcionamiento de un AG:
— Se crea una población inicial generando individuos aleatoriamente.
— Repetimos hasta que se alcance el individuo óptimo o el número máximo de generaciones:
— Asignar un valor de supervivencia a cada miembro de la población.

— Emparejar un grupo de padres para crear desdendencia.
Implementación
Los AG se adaptan específicamente a los problemas que van a resolver.
No hay un marco teórico genérico para aplicarlo a todos los problemas.
Es difícil establecer dicho marco.
Si es muy genérico, resulta trivial.
Si es muy específico, no se puede adaptar a todos los problemas.
Aplicaciones
Optimización de una función simple.
Los cromosomas son vectores numéricos que representan el rango de variación.
La función de selección es el propio valor de f(x).
El resultado se muta con una probabilidad dada.
Problema del viajante.
Cada cromosoma es un vector con una permutación de todas las ciudades, lo cual representa un camino para visitarlas todas.
La función de selección depende de los pesos de los distintos arcos del grafo.
Se muta el vector (se intercambian algunos de sus elementos) con una probabilidad dada.
Representación
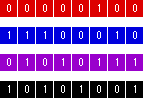
Cadenas binarias (generalmente) de longitud determinada por el número de variables existentes en una solución y el número de bits necesarios para representarlas; cromosomas o estructuras
{kind=link}
Procedimiento
Conclusiones
¡ Es poco sensible a los mínimos locales, lo cual le confiere robustez, en contraste con las redes neuronales clásicas.
¡ Asimismo, no depende de las condiciones iniciales, debido a que se usa búsqueda estocástica y ésta hace al principio un gran número de intentos aleatorios.
¡ Funciona de forma paralela, por lo que pueden usarse en sistemas distribuidos para mejorar más la velocidad de búsqueda.
— Inconvenientes del uso de los AG
¡ No hay un marco teórico genérico establecido.
¡ Si la población inicial es cercana a la solución óptima, los GA tardarán más que las técnicas de resolución tradicionales.
— El GA perderá mucho tiempo comprobando soluciones sub-óptimas.
¡ Hacen buenas estimaciones de la solución óptima, pero no la calculan exactamente.
¡ El usuario debe determinar cómo de cerca está la solución estimada de la solución real.
— La proximidad a la solución real dependerá de la aplicación en concreto.
REDES NEURONALES
CARACTERÍSTICAS DE RNAS
• El estilo de procesamiento es mas bien como el de procesamiento de señales, no simbólico. La combinación de señales para producir nuevas señales contrasta con la ejecución de instrucciones almacenadas en memoria
• La información se almacena en un conjunto de pesos, no en un programa. Los pesos se deben adaptar cuando le mostramos ejemplos a la red.
• Las redes son tolerantes a ruido: pequeños cambios en la entrada no afecta drásticamente la salida de la red.
• Los conceptos se ven como patrones de actividad a lo largo de casi toda la red y no como el contenido de pequeños grupos de celdas de memoria.

COMPARACIÓN CEREBRO – ORDENADOR
ARQUITECTURAS DE RNAS
• Perceptrones de un solo nivel
• Perceptrones de varios niveles
Funciones neuronales
• Función sumatorio
Si ∑eX * PX es mayor que el umbral entonces genera una señal de salida
Funciones neuronales
b) Función de Activación
• El resultado de la ∑ debería ingresar a una Función de Activación antes que a una función de Transferencia. Esto permite variar la salida en función del tiempo y la experiencia
Ventajas
• Aprendizaje adaptativo: lo necesario es aplicar un buen algoritmo y disponer de patrones (pares) de entrenamiento.
• Auto-organización => conduce a la generalización
• Tolerancia a fallos: las redes pueden aprender patrones que contienen ruido, distorsión o que están incompletos.
• Operación en tiempo real: procesan gran cantidad de datos en poco tiempo.
• Facilidad de inserción en tecnología ya existente.
Ejemplo de entrenamiento
Aprender las entradas:
Entrada = {1,1} deberá producir la salida = {1}
Entrada = {0,0} deberá producir la salida = {0}
Pesos iniciales: {-1,-1}
Constante de aprendizaje: {1}
Función de transferencia: rampa
Si el resultado de la suma < 0,
entonces la salida = 0
Si el resultado de la suma >= 0 y <= 1,
entonces la salida = entrada
Si el resultado > 1,
entonces la salida = 1
Recordemos que:
Entrada = {1,1} debería producir la salida = {1}
De momento, la salida obtenida fue = {0}
Por tanto, hace falta… un ajuste sináptico
Constante = 1
Error = salida esperada - salida obtenida
Peso nuevo = Peso antiguo +
( Error * Entrada * Constante)
|
Ajuste para el peso 1
Error = 1- 0 = 1
Peso nuevo = -1 + (1 * 1 * 1) = 0
Ajuste para el peso 2
Error = 1 - 0 = 1
Peso nuevo = -1 + (1 * 1 * 1) = 0
Conclusiones
1. Si presentamos nuevamente el segundo objeto, verificaremos que el resultado calculado es el esperado
2. Se considera, entonces, que la red ha aprendido
Diferencias entre programas
tradicionales y RN:
• Un programa tradicional es un conjunto de instrucciones que representan objetos del mundo real que codifican el conocimiento; ejecutará siempre lo que está codificado en las instrucciones.
• En una RN ningún conocimiento está codificado; es necesario enseñar presentando ejemplos. Básicamente, el conocimiento, al ser enseñado,
Diferencias entre programas
tradicionales y RN:
se almacena en forma de pesos (valores) que darán a la red el comportamiento deseado.
• Simulando un comportamiento parecido al del ser humano
Diferencias entre programas
tradicionales y RN:
se almacena en forma de pesos (valores) que darán a la red el comportamiento deseado.
• Simulando un comportamiento parecido al del ser humano
Tipos de Redes Neuronales
• Redes Neuronales Supervisadas (RNS)
Perceptrón (PRT)
Adalina (ADA)
Perceptrón Multicapa (MLP)
• Otras Redes Neuronales Supervisadas (ORS)
Funciones de Base Radial (RBF)
Redes de Regresión Generalizada (GRN)
Redes Neuronales Probabilísticas (RNP)
• Redes Neuronales Autoorganizadas (RAT)
Redes Competitivas (RNC)
Mapas Autoorganizados (SOM)

ALGORITMOS GENÉTICOS
CONTENIDO
— ¿Qué son los algoritmos genéticos?
— ¿Cómo funcionan?
— Implementación de los AG
— Aplicaciones
— Representación
— Conclusiones
Inteligencia Artificial
— Problemas que no se pueden resolver por un enfoque algorítmico tradicional.
— Nueva forma de manejar la imprecisión y la incertidumbre.
— Algoritmos basados en los principios de la evolución natural .
— Se utilizan en problemas donde no se pueden encontrar soluciones o estas no son satisfactorias
Algoritmo Genético?
— Se aplican sobre una población representada de forma abstracta como cromosomas, que son la codificación de soluciones candidatas a un problema.
— La evolución comienza desde una población aleatoria.
— En cada generación, la selección natural elegirá que individuos son aptos, modificandolos y mutándolos para la siguiente generación.
— “Los Algoritmos Genéticos son algoritmos matemáticos de optimización de propósito general basados en mecanismos naturales de selección y genética, proporcionando excelentes soluciones en problemas complejos con gran número de parámetros”.
— ¿Cómo funcionan?
— Para resolver un problema usando AG necesitamos:
— Representar soluciones.
— Tradicionalmente una cadena de bits.
— Medir la calidad de cada solución con respecto al problema a resolver.
— Se usa una función de selección.
— Esquema de funcionamiento de un AG:
— Se crea una población inicial generando individuos aleatoriamente.
— Repetimos hasta que se alcance el individuo óptimo o el número máximo de generaciones:
— Asignar un valor de supervivencia a cada miembro de la población.
— Seleccionar a un conjunto de individuos que actuarán como padres usando como criterio su probabilidad de supervivencia.
— Emparejar un grupo de padres para crear desdendencia.
— Combinar la descendencia con la población actual para crear nueva población.
Implementación
Los AG se adaptan específicamente a los problemas que van a resolver.
No hay un marco teórico genérico para aplicarlo a todos los problemas.
Es difícil establecer dicho marco.
Si es muy genérico, resulta trivial.
Si es muy específico, no se puede adaptar a todos los problemas.
Aplicaciones
Optimización de una función simple.
Los cromosomas son vectores numéricos que representan el rango de variación.
La función de selección es el propio valor de f(x).
El resultado se muta con una probabilidad dada.
Problema del viajante.
Cada cromosoma es un vector con una permutación de todas las ciudades, lo cual representa un camino para visitarlas todas.
La función de selección depende de los pesos de los distintos arcos del grafo.
Se muta el vector (se intercambian algunos de sus elementos) con una probabilidad dada.
Representación
Cadenas binarias (generalmente) de longitud determinada por el número de variables existentes en una solución y el número de bits necesarios para representarlas; cromosomas o estructuras
Procedimiento
Conclusiones
¡ Es poco sensible a los mínimos locales, lo cual le confiere robustez, en contraste con las redes neuronales clásicas.
¡ Asimismo, no depende de las condiciones iniciales, debido a que se usa búsqueda estocástica y ésta hace al principio un gran número de intentos aleatorios.
¡ Funciona de forma paralela, por lo que pueden usarse en sistemas distribuidos para mejorar más la velocidad de búsqueda.
— Inconvenientes del uso de los AG
¡ No hay un marco teórico genérico establecido.
¡ Si la población inicial es cercana a la solución óptima, los GA tardarán más que las técnicas de resolución tradicionales.
— El GA perderá mucho tiempo comprobando soluciones sub-óptimas.
¡ Hacen buenas estimaciones de la solución óptima, pero no la calculan exactamente.
¡ El usuario debe determinar cómo de cerca está la solución estimada de la solución real.
— La proximidad a la solución real dependerá de la aplicación en concreto.

Suscribirse a:
Comentarios (Atom)